

In the ever-evolving landscape of data management, orchestrating complex workflows efficiently is paramount for organizations like Tipalti. As our data operations expanded beyond what Rivery and DBT can offer, we recognized the need for a more robust data pipeline orchestrator. Enter Apache Airflow, an open-source platform renowned for its flexibility and scalability in managing batch-oriented workflows.
We decided to adopt Apache Airflow primarily because of its ability to offer more control over task dependencies between the tools in our data ecosystem. This granular control allows us to streamline our workflows effectively, ensuring each task is executed seamlessly and in accordance with the dependencies defined.
Moreover, embracing Apache Airflow has empowered our data engineering team with extensive knowledge about Kubernetes. Leveraging Kubernetes alongside Airflow has enabled us to optimize resource utilization, enhance scalability, and improve overall efficiency in managing our data infrastructure. This synergy between Airflow and Kubernetes has not only bolstered our data orchestration capabilities but hase enriched the skill set of our team, fostering innovation and adaptability in our data management practices.
Embracing Apache Airflow
At Tipalti, our data ecosystem is comprised of diverse sources ranging from SQL Server and MongoDB to S3 files and APIs, among others. We leverage Rivery for data ingestion and DBT for transformative analytics within our Snowflake Data Warehouse. Apache Airflow emerged as the linchpin orchestrating these intricate processes seamlessly.
In addition to Rivery and DBT, Python plays a crucial role in our data operations. We utilize Python not only for data ingestion but also occasionally for data transformation tasks. Its versatility and extensive libraries position Python as an ideal choice for handling various data formats and processing requirements. Whether it’s extracting data from APIs, parsing files stored in S3, or performing complex transformations, Python provides the flexibility and efficiency needed to streamline these tasks within our data workflows. Integrating Python alongside Airflow, Rivery, and DBT further enhances our ability to orchestrate end-to-end data pipelines efficiently, ensuring seamless data flow and analytics across our diverse sources and systems.
Unpacking Apache Airflow’s Architecture
Apache Airflow operates on the principles of Directed Acyclic Graphs (DAGs), where workflows are represented by interconnected tasks. This architecture comprises key components like the Scheduler, Executor, and Workers. Other typical components of an Airflow architecture include a database to store state metadata, a web server used to inspect and debug Tasks and DAGs, and a folder containing the DAG files. Each DAG delineates task dependencies and their execution order, facilitating streamlined data flow management.
Taken from Airflow’s official website:
“A DAG contains Tasks (action items) and specifies the dependencies between them and the order in which they are executed. A Scheduler handles scheduled workflows and submits Tasks to the Executor, which runs them. The Executor pushes tasks to workers.”
A sample DAG is shown in the diagram below:

Airflow Architecture Diagram:
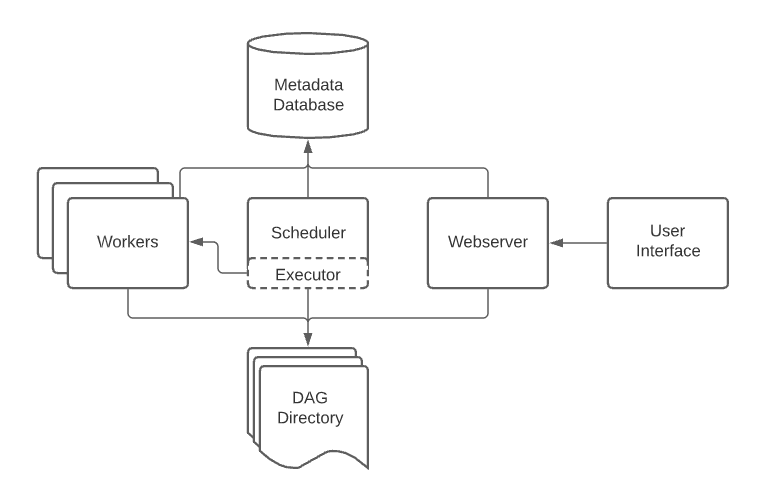
***The image was taken from Airflow’s official website.
KubernetesExecutor: Powering Scalability and Isolation
Tipalti’s deployment of Apache Airflow is orchestrated via Kubernetes, leveragingKubernetesExecutor for task execution.
This choice offers unparalleled benefits:
- Resource Isolation: Tasks operate within dedicated pods, ensuring optimal resource utilization and isolation.
- Dynamic Resource Allocation: Kubernetes allows fine-grained control over resource allocation, accommodating varying workload demands effortlessly.
- Flexibility: Different Docker images can be assigned to individual tasks, enhancing customization and environment isolation.
While the KubernetesExecutor presents notable advantages, it’s imperative to address complexities in configuration and potential latency issues during pod initialization, especially for short-interval task scheduling.
We opted for the KubernetesExecutor primarily due to its seamless integration with our existing Kubernetes infrastructure. As our organization has heavily invested in Kubernetes for container orchestration and resource management, utilizing the KubernetesExecutor aligns with our overarching strategy of leveraging Kubernetes as a foundational technology across our entire data ecosystem.
Git Synchronization: Ensuring DAG Consistency
Maintaining version control and ensuring DAG consistency are paramount in our data orchestration framework. While Airflow’s native git-clone container offers synchronization capabilities, we have encountered challenges with reliability and dependency on network connectivity.
Previously, we struggled with reliability issues, especially during network disruptions, which affected the synchronization process of Airflow’s git-clone container. Additionally, dependencies on external services, like our Azure TFS, posed a significant risk, as any downtime in TFS would lead to Airflow being inaccessible.
To mitigate these issues, we devised a resilient solution:
- Persistent Volume (PV): We established a dedicated PV for the DAGs folder, ensuring data persistence and accessibility across Airflow components.
- Custom Synchronization Mechanism: An independent Flask app orchestrates DAG synchronization via API calls triggered by Azure Pipelines. This approach ensures continuous synchronization and minimizes dependencies on external factors.
Optimized Resource Allocation with Kubernetes Nodes
In our pursuit of optimization, we segregated management pods (webserver, scheduler) from data processing pods onto distinct Kubernetes nodes. This strategic allocation optimizes resource utilization, enhances performance, and fortifies system stability.
Next Steps…
Addressing potential latency issues during pod initialization remains a priority. For our next phase, we’re exploring the adoption of CeleryKubernetesExecutor, a combination of the Kubernetes executor and Celery executor. Stay tuned for our upcoming insights!
Conclusion: Charting the Course Ahead
Our journey with Apache Airflow at Tipalti exemplifies the transformative power of robust data orchestration tools. Through meticulous architecture design and innovative solutions, we’ve streamlined our data workflows, bolstered scalability, and fortified reliability.
As organizations navigate the complexities of modern data ecosystems, Apache Airflow stands as a beacon of agility and efficiency. By embracing its capabilities and leveraging Kubernetes orchestration, enterprises can chart a course toward data-driven excellence in the digital age.