

How do you rebuild a webhook delivery system with Kafka while keeping your existing system fully operational?
At Tipalti, delivering business-critical notifications as soon as they occur is one of many integration cores for our business and an important aspect of our product.
First, here is a little background on why we built it. Our customers can register webhooks from the application if they want to be notified about key events in their automated business flows. When these events occur, our application makes HTTP requests to these webhook URLs along with the required data. This way, customers can build custom integrations with Tipalti.
As our architecture evolves from a monolithic system to a microservices-based one, we found it essential to enhance our current webhook system architecture and technology. This upgrade is necessary to meet the scalability demands of our expanding customer base. Simply patching and applying workarounds to address issues and improve the system will never fully resolve the underlying problems.
To achieve our goals of quickly delivering value, avoiding functionality disruption, and minimizing migration overhead for our customers, we decided to leverage Apache Kafka for our webhook delivery system. Kafka’s robust streaming platform offers several key benefits that align perfectly with our requirements—which will be presented shortly. By adopting Kafka, we are not only addressing the current limitations of our webhook system but are also laying down the foundation for future innovation. This strategic move enables us to rapidly deliver new features and improvements while keeping our services stable and reliable for our customers.
Unlike other articles on building and designing a webhook system, here we’ll focus on successfully integrating between new and legacy systems.
Read on to learn about the first steps of an agile and practical journey of migrating from an outdated webhook system to a modernized solution driven by the company’s expanding customer base. Here, we will focus on enhancing fault tolerance, availability, and scalability, helping you reach production in small and safe steps while employing advanced technologies such as Kafka, Change Data Capture (CDC), and microservices.
Ready? Let’s go.
Step One: Learn the History, Understand the Context
Before you can start planning a new system, you need to fully understand the context of your project. This means identifying the new system’s purpose, scope, and objectives, as well as your users’ needs, expectations, and behaviors. For that, you need to start digging into the history and analyze the existing systems your new one will interact with.
Start collecting current system metrics like:
- Number of events/sec
- Maximum event size
- Edge cases of events burst
- Leading customers
- Usage patterns
You need to learn how, together, these systems can support your business processes, data flows, and information structures. By understanding the context, you can define requirements, constraints, and opportunities for your system integration.
Step Two: Designing the Interface
Once you clearly understand the context, you can proceed with designing the interface between the new system and your existing systems, prioritizing compatibility, consistency, and reliability. This involves considering the format, frequency, and direction of data transfer, along with protocols, standards, and communication methods. Additionally, you need to ensure the interface aligns with usability, accessibility, and security principles.
In our scenario, we’ve outlined requirements for sustaining a highly available and scalable system with fault-tolerance, as well as introduce new ones we need to develop:
- Scalability: the system must accommodate varying loads and changes through horizontal scalability, capable of handling millions of events per second.
- Event Order Guarantee: the existing system ensures some form of event ordering. It’s essential to prioritize maintaining the sequential delivery of events whenever possible, even within the new system.
- Webhook Delivery: ensure the system reliably delivers webhooks.
- Retry Support: given that webhook delivery failures can occur due to receiving-end issues like bugs or system downtime, implement retry mechanisms with exponential backoff to handle failed deliveries.
Step Three: Deciding on the Tech Stack
Imagine the current webhooks notification system as a highway with a maximum capacity of cars (events) it can hold over a certain period of time. As more cars—or events—are on the road, you get “traffic jams,” resulting in events lagging to reach their destination.
So, it’s clear that we need to build a new “road” capable of supporting a much higher number of events that can dynamically scale when required. This way, each event should reach its destination in the same order that was triggered and in a reasonable timeframe.
Having already utilized RabbitMQ, it made sense for us to explore whether it could also meet the demands of our webhook system. Ultimately, we determined that opting for Kafka Confluent over RabbitMQ offered several advantages.
Firstly, Kafka is known for its distributed architecture, which inherently provides better scalability for designing a webhook system and better fault tolerance than RabbitMQ. Kafka’s partitioning mechanism allows for efficient handling of large volumes of data, ensuring high throughput and making it ideal for systems that need to handle a massive amount of events, such as webhook delivery systems.
Secondly, Kafka’s persistent storage model and log-based architecture make it highly reliable for event streaming. It guarantees data durability and maintains the order of events, which is crucial for ensuring the integrity of webhook deliveries, especially when dealing with critical business events.
Moreover, Kafka’s ecosystem—including tools like Kafka Connect and Kafka Streams— provides comprehensive support for data integration and stream processing, which can streamline the development and management of webhook systems. It also offers robust monitoring and management capabilities, allowing for easier maintenance and troubleshooting.
While RabbitMQ is a popular choice for message queuing systems, Confluent Cloud For Kafka stands out for its scalability, reliability, and extensive feature set, making it a preferred option for designing high-performance webhook systems.
The Monolith Challenge
We now have Kafka to help us out. But what about the current (and outdated) webhooks notification system—a monolith where all our tables reside on a single database?
The first challenge we wanted to solve was scaling up to accommodate the growing number of events driven by our growing customer base. In the current monolithic setup, only two runner processes manage fetching events from the database, dispatching them to end clients, updating event status, and handling retry mechanisms for failed events. This creates a clear need to decompose the business logic of these runners into smaller, more manageable units of responsibility. Doing so is essential, especially given our resource constraints within the monolith, hindering our ability to scale effectively.
Figure 1: Current Webhook System, High-Level Design
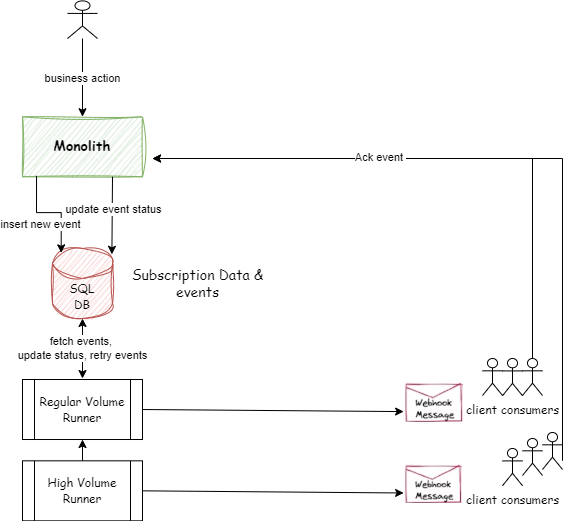
As the breakdown of the monolith continues to unfold, the initial phase involves replacing the runner process with a new webhook infrastructure composed of microservices, with Kafka serving as the event delivery system.
If you’ve ever migrated from a monolith to microservices, you know there are obstacles along the way. At this point, we will focus on building the webhooks system infrastructure and related microservices. Later, we’ll handle all public API webhooks configurations and registrations to migrate from a monolith to relevant microservices.
You might wonder, “How do events stored in the monolith system find their way into the Kafka topic?” One approach is to employ an outbox pattern, enabling data to be saved in two sources within a single transaction. However, from our experience, this solution may entail more effort and potentially lead to decreased database performance. The preferred method involves leveraging Confluent CDC connectors, which offer the following benefits:
“CDC enables organizations to maintain data integrity and consistency across all systems and deployment environments and alternative solutions to batch data replication. Furthermore, it empowers organizations to utilize the appropriate tools for specific tasks by facilitating the movement of data from legacy databases to purpose-built data platforms.”
Once the events are integrated into the webhooks system, the delivery process can commence.
Step Four: Initial Design and Development
As our journey unfolds, marked by unforeseen twists and turns, we’ve opted to break down the migration process into distinct phases. Each phase not only significantly enhances our product but also delivers tangible benefits to our customers.
Here’s an overview of the high-level phases:
- Utilize the existing webhooks monolith database tables while leveraging Kafka to construct a new microservices infrastructure for webhooks. Initially, only new customers will utilize the new system.
- Gradually transition low, medium, and high-volume events to utilize the newly established webhooks infrastructure. At this stage, all customers will be seamlessly integrated into the upgraded infrastructure. At the same time, meticulous attention is devoted to designing and developing robust backward compatibility and a rollback plan to ensure a smooth and secure transition.
- Extract the webhooks monolith database tables and allocate them to the appropriate microservice dedicated to managing webhooks configuration and event history.
Let’s focus on the first phase:
- Events are created and saved in the monolithic database.
- Using the Confluent MS-SQL connector, specific events (events that should be delivered to new customers) get published into a Kafka topic.
- Webhooks Manager microservice consumes the events, validates them, filters them, and creates a webhook message with additional details. This message is then produced into a relevant topic based on the type of customer (high/medium/low events volume).
- The Dispatcher microservice is responsible for delivering the webhook’s messages to the customers.
- The Retry Manager microservice will handle all undeliverable messages read from a “failed messages” Kafka topic. Using an exponential backoff mechanism, the Retry Manager will retry to deliver webhook messages to their destination.
Eventually, microservices will generate RabbitMQ (RBMQ) events, which the monolith will consume to update the “source of truth”—also known as the webhooks database table.
It’s essential to highlight that throughout this process, the monolith database will consistently remain up-to-date with every webhook event triggered in the system. It will also seamlessly interact with both old and new delivery systems.
Figure 2: First Phase, High-Level Design
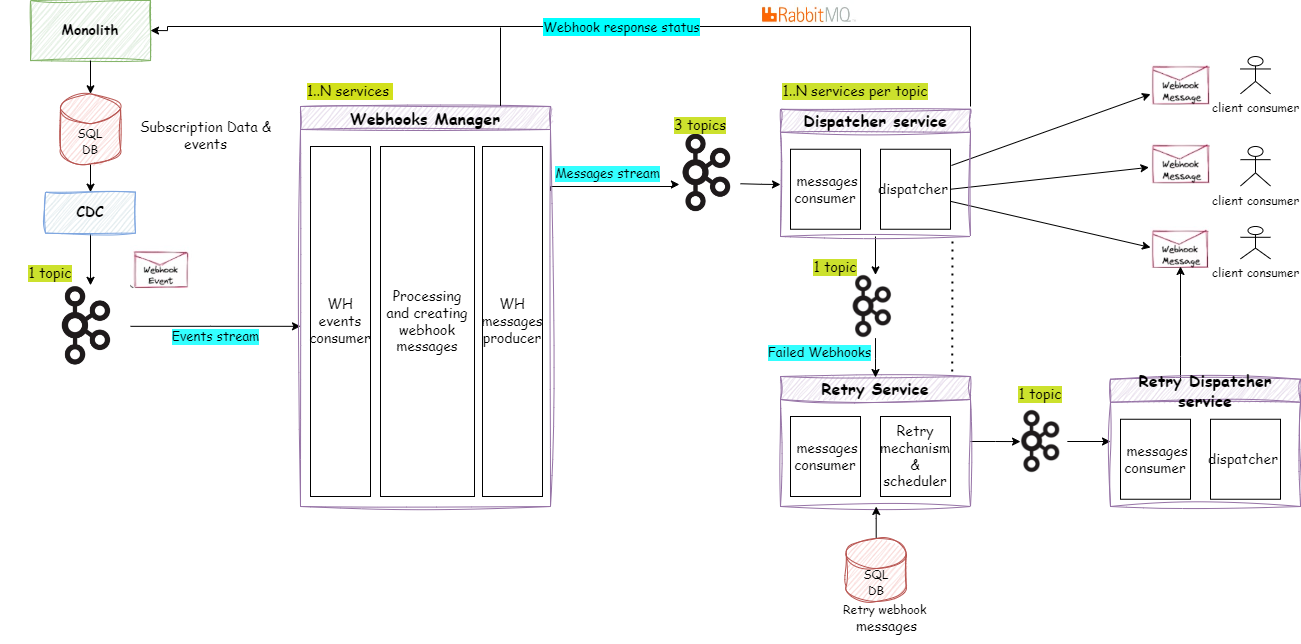
Upon reviewing the High-Level Design (HLD) at this stage, you might wonder: Why are all these topics necessary? What is the composition of these topics? And how does this design guarantee the order of events?
To address these questions, we’ll take a closer look at how Kafka operates internally.
As events are captured and sent to the initial topic (via the Kafka CDC Connector), which we’ll refer to as the “CDC Topic,” it’s essential to understand some fundamental concepts about topics:
- Topics serve as specific types of data streams, resembling queues but with distinct characteristics.
- Each topic is divided into partitions, with the flexibility to have one or multiple partitions, much like folders in an operating system.
- When producing a message without specifying a key, Kafka distributes messages across partitions in a round-robin manner, potentially compromising delivery order at the partition level. However, assigning a key to messages ensures consistent delivery to the same partition.
- Every message is stored on the broker disk and assigned a unique offset at the partition level, enabling Kafka’s durability and recovery capabilities, which sets it apart from traditional messaging systems.
- Consumers utilize offsets to read messages sequentially from the oldest to the newest. In case of consumer failure, they resume reading from the last offset.
In our design, the “CDC Topic” maintains all events within a single partition, preserving their order without the need for message keys at this stage.
Subsequently, the webhook manager consumes these messages and, after minimal processing, segregates them into three “Dispatcher Topics” based on customer type (high/medium/low event volume). To maintain message order, topics are produced using a key. Our chosen key format ensures messages pertaining to a customer with the same event type and entity are consistently ordered within the same partition.
Determining the ideal number of partitions for each topic is a nuanced process, but tools like the Confluent calculator can help with this. By leveraging metrics gathered earlier, the calculator recommends the number of partitions needed based on usage and traffic projections.
Each “Dispatcher Topic” is initially configured with at least three partitions to facilitate horizontal scaling when necessary. Messages are consumed by the Dispatcher service and dispatched to customers. In the event of delivery failure, messages are redirected to the “Retry Topic” for subsequent processing by the Retry Manager service.
The Retry Manager retrieves messages awaiting to be resent, producing them to a “Retry Dispatcher Topic” for consumption and subsequent dispatch to end customers. Given the anticipated lower volume of failed messages, the latter two topics are provisioned with only one partition each.
Step Five: Testing the Webhook System
After designing and developing the new system to work alongside the current one, you need to test the integration between them.
The testing phase is crucial for verifying the integration is working as intended and for identifying and resolving any issues or errors that might have arisen during the integration process.
The integration needs to be tested at different levels, including unit, functional, performance, and user acceptance testing, which require various tools, techniques, and metrics to measure the results. You’ll also need to involve stakeholders, like users, managers, and developers, in the testing process and collect any feedback and suggestions they might have.
Step Six: Designing the Rollout
Once you’re done testing the integration, you’re ready to implement it into your production environment.
To ensure a smooth and seamless integration, Tipalti’s product and engineering teams decided only new customers would serve as the first phase of the new webhook system, making sure there are no system-breaking changes or special adjustments required on the customers’ side.
You’ll need to plan and schedule the implementation and communicate it with stakeholders. It’s important the implementation does not disrupt business operations and that it delivers the expected benefits and value.
Last But Not Least: Planning the Next Phases
The new system is now fully integrated and maintained within the old legacy system. But remember, this is only the first phase in the journey of migrating over from the old system to the new one, and eventually, that old system will need to be retired.
To accomplish this, we’ll need to pre-plan our next goals and revisit the steps mentioned above according to the updated context, interface design, testing, implementation, and lessons learned along the way.